

EMPHASIS: a global solution for the intelligent automation of backoffice processes
EMPHASIS
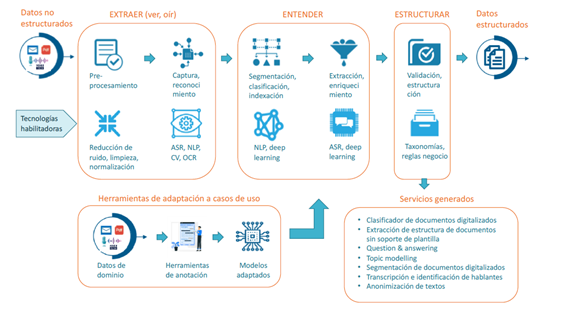
The integration of speech processing and natural language technologies allow the structuring of unstructured content until now, such as documents (invoices, delivery notes, deeds, building permits, municipal licences,...), without the need for them to have an associated template , or calls (in call centers for example).
The aim of the project is to convert all that content (documents and calls) into data, in order to be able to manage it, analyze it and optimize the associated processes, in order to advance in a real digital transformation, which otherwise seems impossible. It is not about doing digitally the same thing that we are doing now. It consists of starting from data to define the optimal flows and processes that guarantee a total, scalable, robust, flexible digitization in the face of changes, that can be adapted to new scenarios and always with reasonable costs.
To do this, another of the key factors is to follow the principles of no-code, or failing that, low-code, that is, develop solutions whose integration and implementation are as transparent as possible, avoiding the costly processes that the solutions entailed. BPM (from English, Business Process Management). It is about developing technology that can be integrated as APIs in third-party solutions, so that its configuration can be carried out by non-expert personnel. In the same way, it is about these APIs encapsulating functions that can be customized, that is, one of the priority objectives of the project is that the functions developed within the framework of the project can then be customized and adapted to different use cases, following the low-code principles.
Therefore, we are talking about developing basic solutions for document and audio processing, but at the same time, we are talking about developing tools and systems that allow the customization of said solutions. We will explain it with an example, if one of the base solutions to be generated allows you to classify documents and say if it is an invoice or a delivery note, the tools that help in the process of annotating other documents and generating the corresponding models will also be generated. of IA, so that in the future the personalized solution can classify documents identifying whether it is a building permit, a deed or a municipal license.
Vicomtech, within the framework of this project in collaboration with various agents, will research and develop speech and natural language processing technologies based on the latest Deep Learning paradigms. More specifically, in relation to speech processing technologies, Vicomtech will focus on the implementation of automatic transcription, biometrics and voice emotion recognition solutions adapted to the domains and needs of companies. Likewise, it will carry out intense R&D activities for the development of solutions aimed at automatic text classification; the detection, recognition and extraction of relationships between entities; the anonymization of sensitive data, question/answer systems and the detection of opinions.
EMPHASIS is a global solution for the intelligent automation of backoffice processes
The solution has an important innovative character, facing various technological challenges to improve processes by extracting, understanding and structuring knowledge through speech and language processing technology and thanks to the implementation of tools that give companies autonomy when it comes to to train Artificial Intelligence technology.
Main technological challenges of EMPHASIS
The main technological challenges of Emphasis are related to the application of the following technologies to different domains and audio and text formats, together with the development of tools to easily adapt them to the real use cases of each client:
- Cognitive Document Automation: its objective is to automate the extraction of relevant content from textual sources of different formats, invoices, delivery notes, e-mails, text documents, FAQ systems, conversations extracted by automatic transcription, to classify content into different categories, domains, feelings, and also extract the keywords and their relationships that allow the understanding of its content. The technology to be used is cutting-edge Deep Learning technology where a paradigm shift has been seen in the last two years thanks to the proliferation of advanced neural architectures that exploit language models with knowledge of the world. Documents that contain images with text inside are also converted and their reading is improved by applying advanced methods on state-of-the-art OCR tools.
- Speech Analytics: its objective is to automate the analysis of data with acoustic content through transformation to text using advanced tools for automatic enriched speech transcription and emotion analysis. The main technology to be used is Deep Learning technology based on the latest contributions from the scientific community to the state of the art and which has shown great improvements with respect to previous Machine Learning technology.
Emphasis is subsidized by the Hazitek program to support Business R&D promoted by SPRI - Society for Competitive Transformation , together with the Department of Economic Development, Sustainability and Environment of Eusko Jaurlaritza - Basque Government.
Emphasis is made up of eleven of the #companies and #institutions with a strong track record in process automation: Teknei, Merkatu, Segula, Eutik, Naturalvox, Gureak, Ibermática, Zucchetti, Vicomtech, University of the Basque Country/Euskal Herriko Unibertsitatea and I3 Ibermatic Institute of Innovation.
Looking for support for your next project? Contact us, we are looking forward to helping you.

